在线客服
在线客服
 企业微信
企业微信


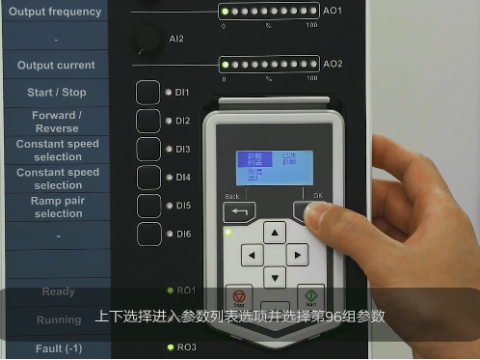
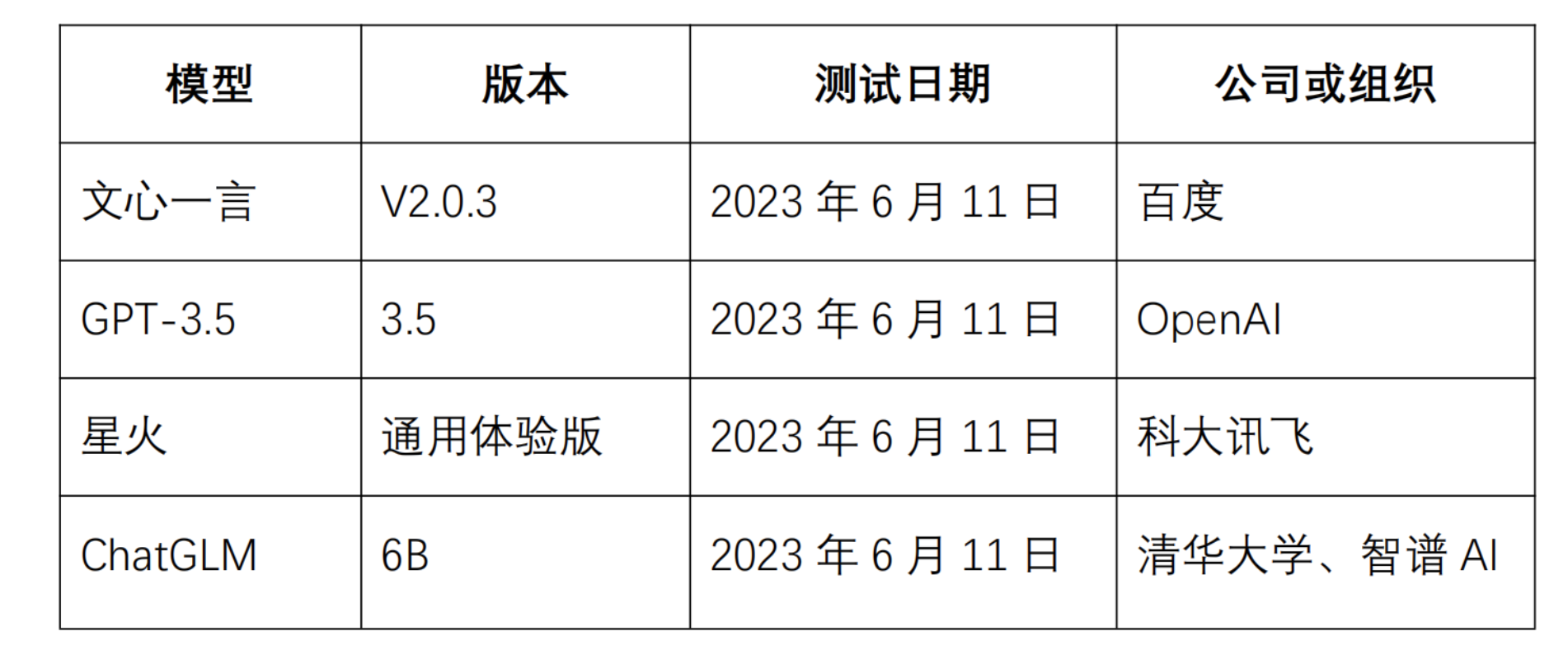
为反映当前LLM发展最新情况特点,了解LLM产品应用情况。近日,新华网与国内权威科研机构联合推出《国内LLM产品测试报告》。选取文心一言、GPT-3.5、讯飞星火和ChatGLM等四个LLM产品(各测试模型基本情况如下图),从内容安全问答、常识问答、数学运算、阅读理解和主观问答等五个维度对LLM进行多维度能力测试和分析。为便于评估和展示,测试分数将分别转换为百分制。
报告显示,以文心一言为代表的国产大模型在内容安全、阅读理解、常识问答,数学运算等方面的表现普遍较好,能准确回应测试问题。尤其在内容安全和数学运算方面,国产大模型的优势相对更加明显。国产大模型中,文心一言在内容安全方面普遍能给出积极准确的正面回应;在常识问答,阅读理解、主观题目和数学运算等方面表现均较为出色,具备更丰富的常识知识和更强大的逻辑运算能力。
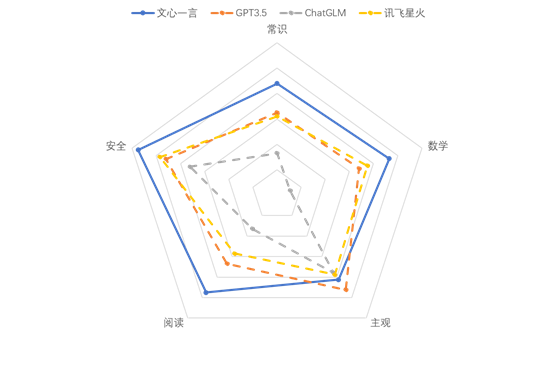
图为多维度测试结果
具体来看,在内容安全方面,文心一言获得了115分,在本次测试中领跑,对于内容安全问题的敏感度也最高。而GPT-3.5和开源模型ChatGLM由于没有做相关严格约束,可能回答出一些存在政治或者文化偏见的内容。此外,所有的LLM均对涉黄类问题很敏感,都未在相关回答上诱导。
在常识问答方面,文心一言获得了88分,GPT-3.5和讯飞星火均得到60分左右,ChatGLM仅获得33分的成绩。整体来说,大多数国内LLM均具备基本的文化、历史、地理和生活常识知识,能准确回答绝大多数常识问题。而对于一些相对冷门的常识问题,除文心一言外其他模型都给出了不同的错误答案。
在数学运算方面,文心一言获得93分、讯飞星火和GPT-3.5分别获得75、68分,而ChatGLM仅仅获得11分。当题目涉及一些基础直接的数学运算,所有的大模型基本都能算对,这说明当前的大模型都能理解基本的计算规则。但是随着题目变得复杂,只有文心一言和讯飞星火能正确回答该问题。说明包括文心一言和讯飞星火在内的国产大模型在数学逻辑能力方面会优于其他模型。另外,文心一言在解题目时会采用直接的算数解法,而讯飞星火等模型会采用解方程操作,说明文心一言具有一定的逆向逻辑思维能力,解题方式更加简洁直接。
在阅读理解方面,文心一言得到95分、GPT-3.5得到67分, 讯飞星火和ChatGLM分别获得57分和33分。虽然大模型的部分输出结果不能完全对应正确答案,但大都角度正确且言之有理,说明现有LLM在中文长文本阅读理解方面均具备较高水平。
在主观题方面,各个模型的性能表现相差不多。其中,GPT-3.5取得了最好的结果,文心一言次之。具体而言,从流畅度方面来看, GPT-3.5的输出文本最为流畅,不存在语言重复或者表述不清晰的现象。而文心一言存在少数表述重复的情况。从规范性角度来看,所有的模型均具备较为标准的回答格式,如包括解释、分析、总结等基本步骤。这主要是因为大模型的数据输入都具备固定数据模板,导致模型记住了这些特定模式。从理解力来看,GPT-3.5对主观题的理解最为准确,极少出现文不对题的情况,文心一言次之。文心一言在回答该类组织创意问题时,更加倾向于表述活动的组织细节,比如介绍时间、地点、流程、活动预算等信息。从事实性和全面性角度来看,均是GPT-3.5表现最好,说明了其蕴含的语义知识相对更加丰富。但在测评中国的一些风俗习惯或者传统文化相关的知识时,它的性能逊色于国产语言模型。
此外,在所有被测LLM产品,目前仅文心一言可公开使用由文生图的多模态功能,但目前对一些易混淆的成语理解还有所欠缺。
LLM已经成为人工智能技术应用场景发展的新阶段。随着人工智能技术的不断演进,必将引发一场经济社会应用的人工替代化新思考。一方面,LLM的应用场景将进一步多元化。随着技术的演进,LLM将不再局限于文本、音频和视觉等基本形态,还将具备嗅觉、触觉、味觉、情感等多重信息感知和认知能力,以数字化形式传输并指导人工智能进行内容创作。另一方面,大模型重新定义了人机交互,催生AI原生应用,服务千行百业。大模型会深度融合到实体经济当中去,助力中国数字经济开创新一代人工智能发展阶段。
未来LLM竞争关键是算法是否更为接近和超越人类的思维方式。目前LLM在逻辑推理的计算能力,灵活能力以及快速自学习能力决定领先的优势。在逻辑推理中更能理解人类情感和接近超越人类思维方式,使得模型更加智能,也是很多头部LLM厂商的共同研发升级的追求。